정확도 측정 방법
정확도 99.6%는 어떻게 측정했나 — 평가셋·지표
바른은 한국어 형태소 분석에서 품사 태깅 99.6%, 어절 분리/복원 99.7%의 정확도를 기록합니다.
이 숫자가 무엇을 뜻하는지, 어떤 평가셋과 지표로 측정했는지를 투명하게 설명합니다.
정확도는 "어떤 데이터로, 어떤 기준으로 쟀는가"에 따라 달라지므로, 측정 전제를 함께 밝히는 것이 중요합니다.
측정에 쓰인 학습·평가 말뭉치
바른은 다음과 같은 대규모 한국어 말뭉치로 학습·평가되었습니다.
| 말뭉치 | 규모 | 비고 |
|---|---|---|
| 세종 말뭉치 | 약 1,200만 어절 | 문어·구어 기반 주력 |
| 모두의 말뭉치 | 약 300만 어절 | 국립국어원 공개 |
| 뉴스(빅카인즈) | 약 1억 어절 | 품사 태깅 보강 |
| 자체 보강·띄어쓰기 증강 | 약 33만 어절 | 분절 규칙에서 저빈도 데이터 보강, 구어 보강, 띄어쓰기 케이스 보강 등 (학습 데이터) |
| 중의성 데이터 | 35,396 문장 / 8,285 표면형 | 공개 데이터셋 |
왜 말뭉치를 밝히나요
정확도 수치는 평가셋이 다르면 비교가 무의미합니다. 바른은 세종·모두의 말뭉치처럼
널리 검증된 표준 말뭉치를 평가 기반으로 삼아, 어떤 데이터에서 나온 수치인지를 분명히 합니다.
두 가지 지표의 정의
바른의 정확도는 서로 다른 두 단계를 각각 측정한 값입니다.
| 지표 | 측정 대상 | 의미 |
|---|---|---|
| 어절 분리/복원 99.7% | 분절(Segmenter) 단계 | 어절을 형태소 경계로 올바르게 끊고, 활용·축약·생략된 형태를 원형으로 복원했는가 |
| 품사 태깅 99.6% | 품사 태깅(PosTagger) 단계 | 분리된 각 형태소에 국립국어원 기준 47품사를 정확히 배정했는가 |
- 어절 분리/복원은 "어디서 끊고, 어떻게 원형으로 되돌렸는가"를 봅니다.
예를 들어
구르+어 먹+어서처럼 활용·축약된 어절을 원형 형태소로 정확히 복원하는지를 평가합니다. - 품사 태깅은 그렇게 나눈 형태소 각각에 붙인 태그가 정답 태그와 일치하는지를 봅니다. 태깅 단계의 정확도는 분절이 먼저 정확해야 의미가 있으므로, 두 지표를 따로 제시합니다.
분절과 태깅을 따로 재는 이유
바른은 분석을 분절 → 품사 태깅으로 나누어 수행합니다. 따라서 정확도도 단계별로 측정해야
어디서 강하고 어디가 개선 여지인지 드러납니다. 두 지표를 하나로 뭉뚱그리면 단계별 품질을 알 수 없습니다.
graph LR
A[정답 말뭉치] --> B[분절 결과 비교];
A --> C[품사 태깅 결과 비교];
B --> D[어절 분리/복원 99.7%];
C --> E[품사 태깅 99.6%];각 형태소 결과에는 probability(softmax 확신도)가 함께 붙어, 모델이 얼마나 확신했는지도 확인할 수 있습니다.
99.6%는 무엇을 어떻게 잰 값인가
품사 태깅 99.6%는 모두의 말뭉치 15만 문장을 대상으로, 국립국어원 기준 47품사 전체를 정답과 대조한 문장 단위 정확도입니다. 채점 기준은 매우 엄격해서, 한 문장 안에서 형태소 하나라도 태그가 틀리면 그 문장 전체를 오답으로 처리합니다. 형태소 단위 정확도가 아니라 문장 전체가 완벽해야 정답으로 인정되므로, 같은 모델이라도 수치가 보수적으로 잡힙니다.
특히 어절 모양은 같지만 분석이 갈리는 중의성(모호성) 케이스를 따로 평가합니다.
| 평가 항목 | 평가 규모 | 측정 내용 |
|---|---|---|
| 전체 47품사 태깅 | 모두의 말뭉치 15만 문장 | 한 형태소라도 틀리면 문장 전체 오답 |
| 모호성(중의성) 해소 | 35,396 문장 / 8,285 표면형 | 같은 표면형의 서로 다른 분석을 문맥으로 구분 |
| VCP(서술격조사 '이') 복원 | 12,129 문장 | '이'가 생략된 문장에서 서술격조사를 정확히 복원 |
- 모호성 해소: 표면형이 같아도 분석이 다른 경우(예
트는→ 틀다/트다)를 문맥으로 구분합니다. 부족한 표면형을 보강해 35,396 문장 / 8,285 표면형 규모의 평가셋을 구축했습니다. 이 평가셋의 구성과 공개 형식은 중의성 평가 데이터셋에서 더 자세히 다룹니다. - VCP 복원: 모두의 말뭉치에서 서술격조사 '이'가 생략된 문장 12,129건을 추출해,
평갑니다(평가/NNG+이/VCP+ㅂ니다/EF)처럼 표면에 드러나지 않은 '이'를 형태소로 복원하는지 평가합니다.
이렇게 까다로운 기준에서도 99.6%가 나온다는 점이 핵심입니다.
성능 그래프로 보기
아래 그래프는 바른의 학습 규모와 평가 정확도를 발표 자료 기준으로 정리한 것입니다.
분절·태깅 모델의 학습 통계부터, 모호성 해소·VCP 복원·문장 전체 태깅 정확도까지를 한눈에 보여줍니다.
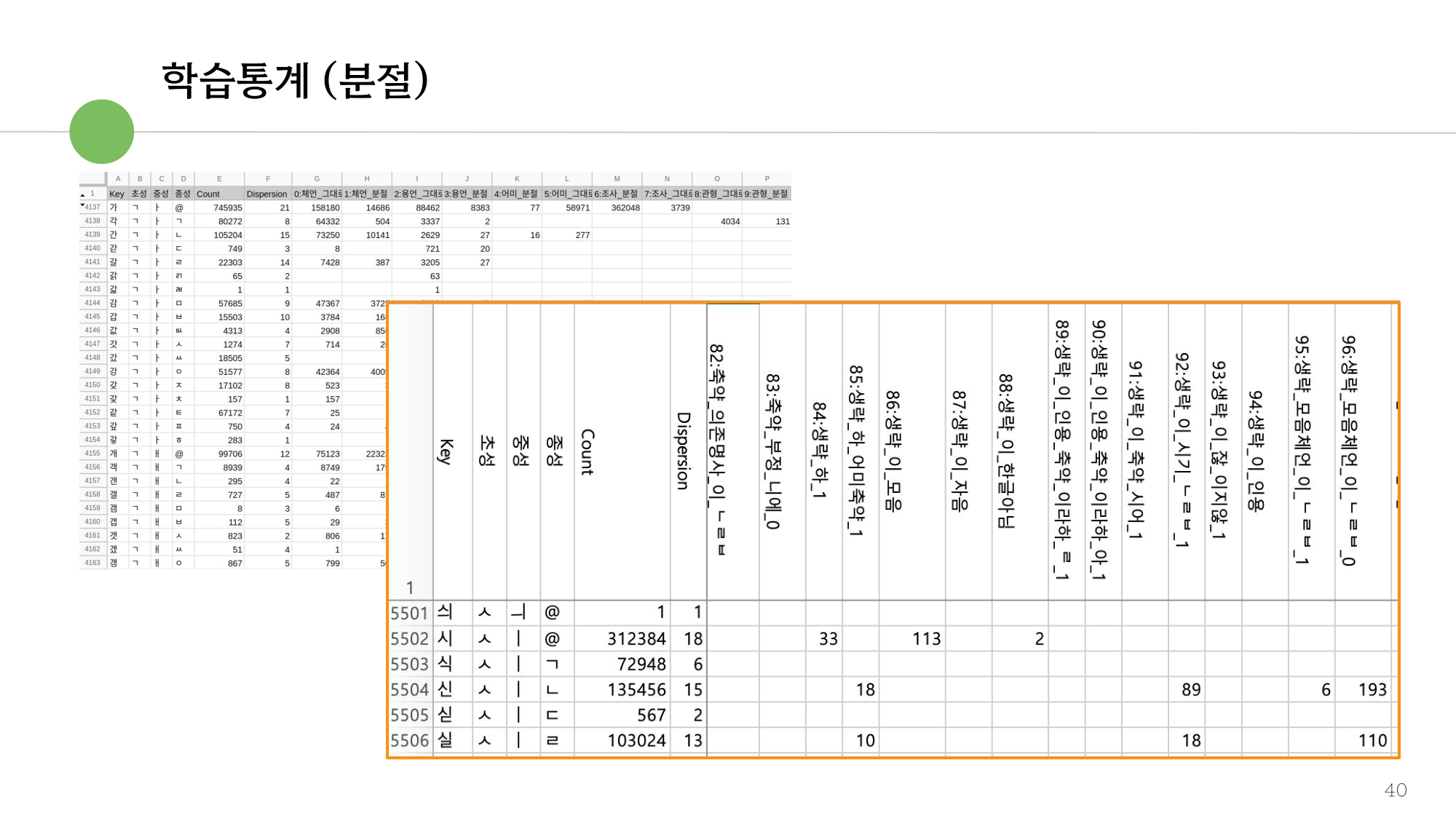 그림 1. 분절(Segmenter) 모델 학습 통계 — 학습 규모와 분절/복원 성능
그림 1. 분절(Segmenter) 모델 학습 통계 — 학습 규모와 분절/복원 성능
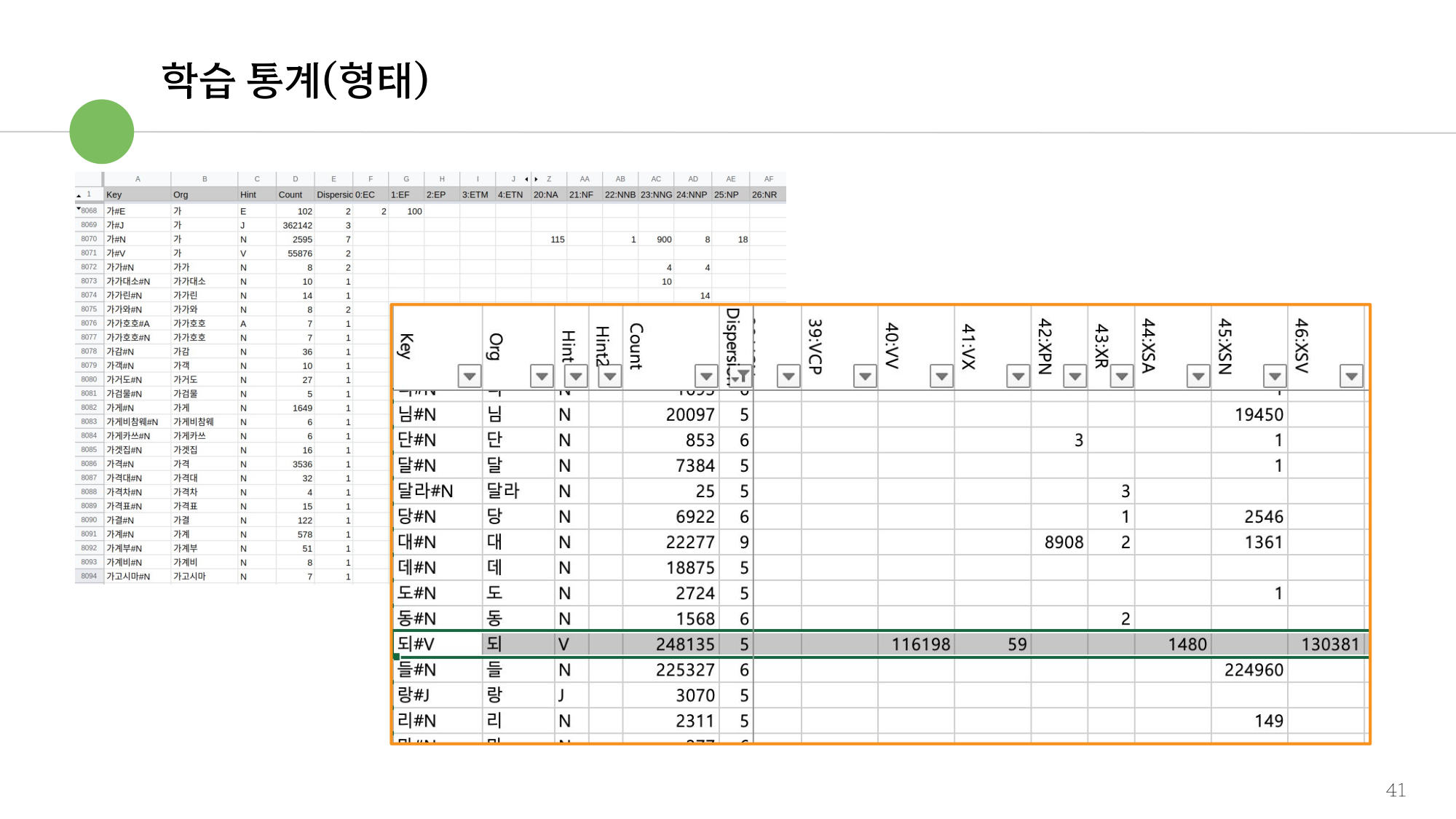 그림 2. 품사 태깅(PosTagger) 모델 학습 통계 — 47품사 학습 규모와 성능
그림 2. 품사 태깅(PosTagger) 모델 학습 통계 — 47품사 학습 규모와 성능
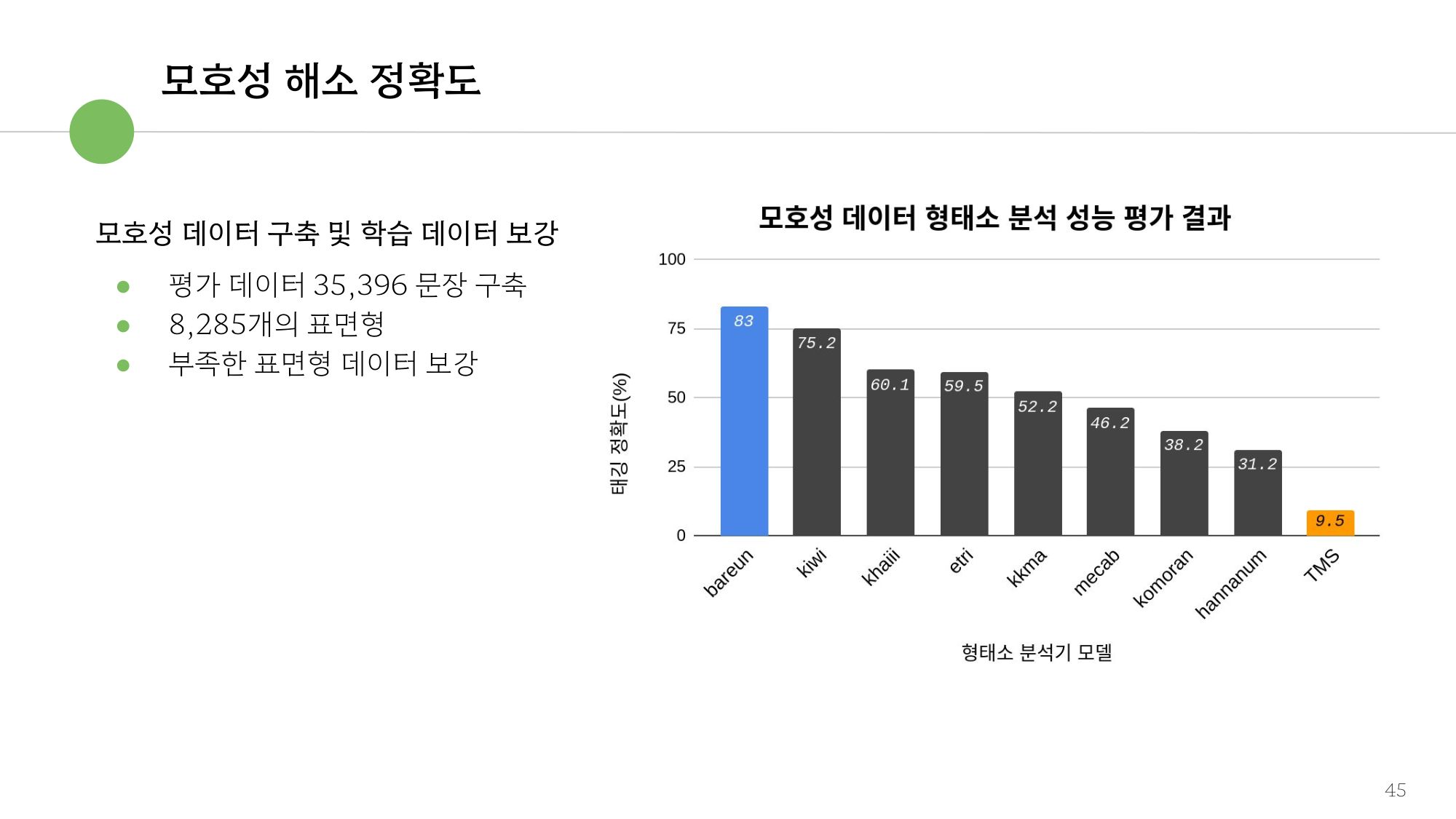 그림 3. 모호성(중의성) 해소 정확도 — 평가셋 35,396 문장 / 8,285 표면형
그림 3. 모호성(중의성) 해소 정확도 — 평가셋 35,396 문장 / 8,285 표면형
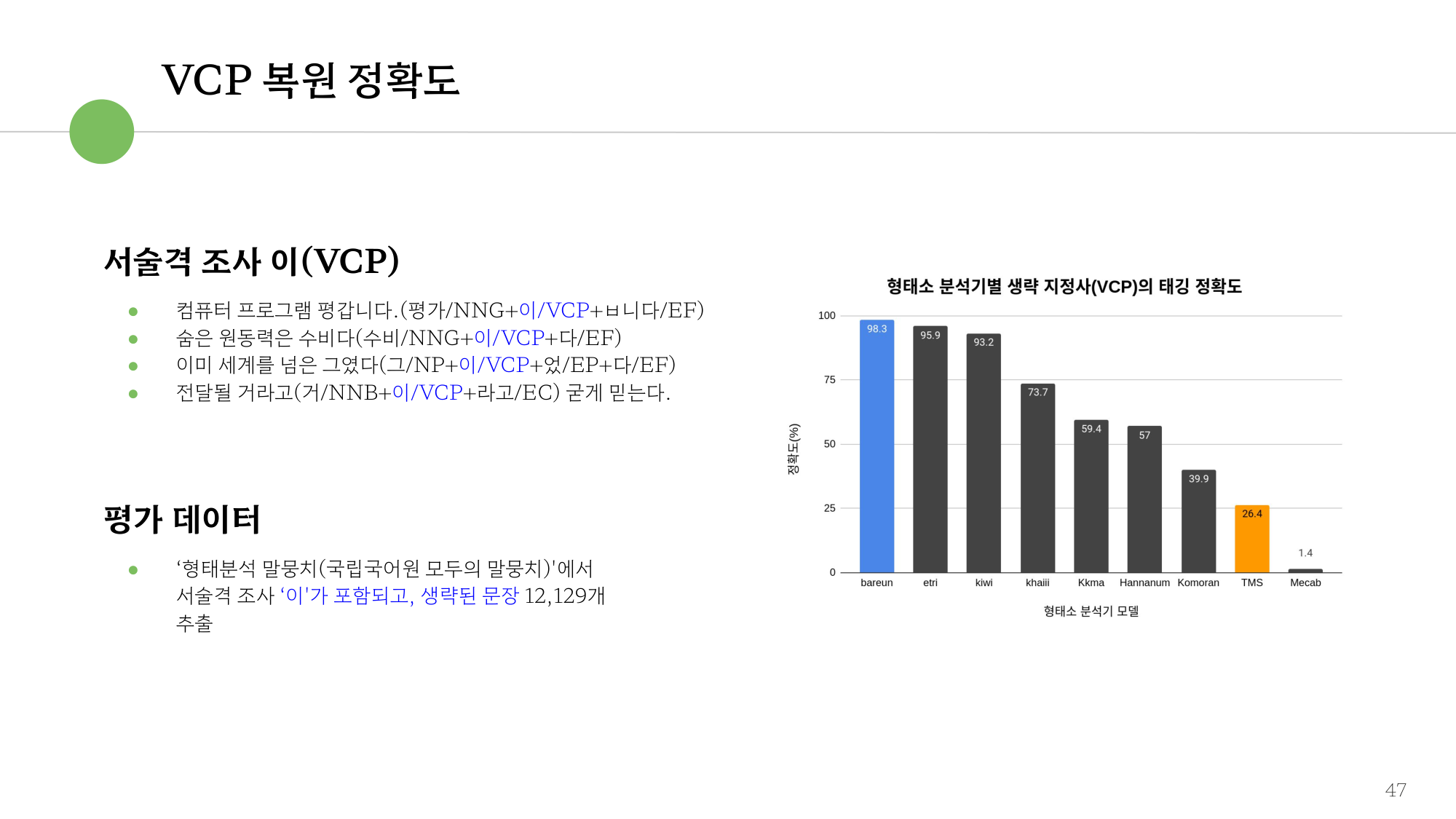 그림 4. VCP(서술격조사 ‘이’) 복원 정확도 — 평가셋 12,129 문장
그림 4. VCP(서술격조사 ‘이’) 복원 정확도 — 평가셋 12,129 문장
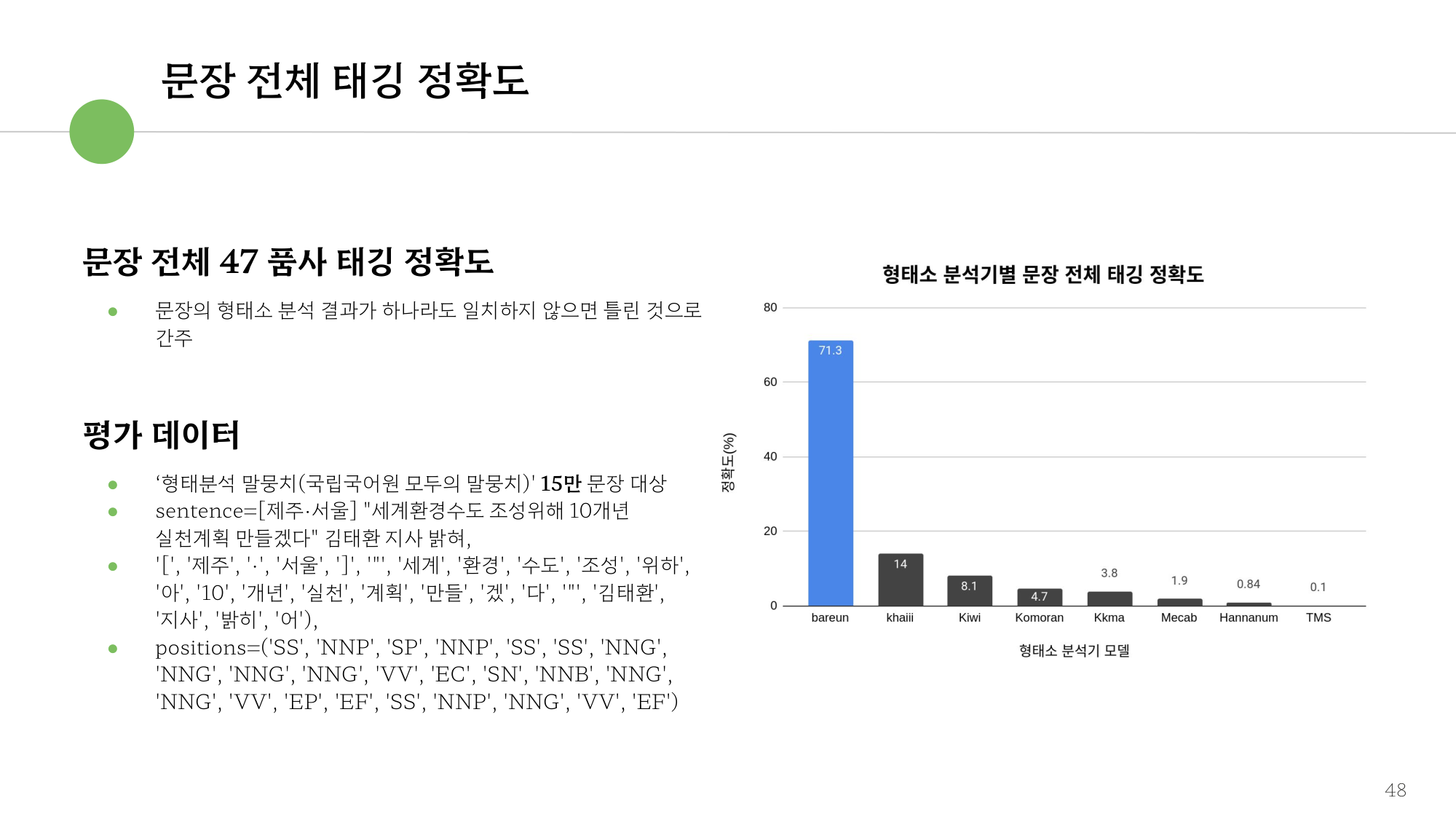 그림 5. 문장 전체 47품사 태깅 정확도 — 15만 문장, 한 형태소라도 틀리면 오답
그림 5. 문장 전체 47품사 태깅 정확도 — 15만 문장, 한 형태소라도 틀리면 오답
그래프 출처
위 5개 그림은 발표 자료 「바른 맞춤법 검사의 내부 원리」의 학습 통계·평가 정확도 슬라이드에서 가져온 것입니다.
수치는 측정 전제에 따라 달라집니다
99.6%·99.7%는 위에 명시한 평가셋과 지표 정의를 전제로 한 자체 측정값입니다. 평가셋·태그셋·정답 기준·전처리 방식이 다르면 같은 분석기라도 수치가 달라질 수 있습니다. 다른 분석기와 비교할 때는 동일한 평가셋·지표·기준에서 측정해야 공정합니다.
관련 문서
- 정확도 살펴보기 — 정확도를 끌어올린 내부 요인
- 정확도는 얼마나 되나요 — 정확도 관련 자주 묻는 질문
- 바른 vs Mecab-ko — 다른 분석기와 비교할 때의 유의점
자주 묻는 질문
Q. 99.6%와 99.7%는 무엇이 다른가요?
99.7%는 분절 단계의 어절 분리/복원 정확도, 99.6%는 품사 태깅 단계의 품사 배정 정확도입니다. 분석이 두 단계로 나뉘므로 지표도 두 개로 나눠 측정합니다.
Q. 어떤 데이터로 측정했나요?
세종 말뭉치(약 1,200만 어절), 모두의 말뭉치(약 300만 어절), 빅카인즈 뉴스(약 1억 어절) 등으로 학습·평가했고, 중의성 데이터는 35,396 문장 / 8,285 표면형 규모로 구축해 공개하고 있습니다.
Q. 99.6%는 형태소 단위 정확도인가요, 문장 단위인가요?
문장 단위입니다. 모두의 말뭉치 15만 문장을 대상으로 47품사 전체를 채점하되, 한 문장 안에서 형태소 하나라도 태그가 틀리면 그 문장 전체를 오답으로 처리합니다. 형태소 단위보다 훨씬 엄격한 기준이라 수치가 보수적으로 잡힙니다.
Q. 서술격조사 '이'가 생략된 문장도 정확히 분석하나요?
네. 모두의 말뭉치에서 '이'가 생략된 문장 12,129건을 추출해 VCP(서술격조사) 복원을 따로 평가합니다.
평갑니다를 평가/NNG+이/VCP+ㅂ니다/EF로 복원하는 것처럼, 표면에 드러나지 않은 '이'를 형태소로 되살립니다.
Q. 우리 데이터에서도 같은 정확도가 나오나요?
평가셋이 다르면 수치는 달라질 수 있습니다. 분야 특화 용어가 많다면 사용자 사전을 등록해 정확도를 높일 수 있고, 사용자 사전은 무중단으로 반영됩니다.
도움이 되었나요?