구어·신조어 적응력
다른 분석기 대비 구어·신조어 적응력
한국어는 구어·축약·신조어가 끊임없이 생겨나는 언어입니다. "감사합니당", "그치만", "ㅂ니당"처럼
구어체·축약형이 섞인 문장은 사전에만 의존하는 분석기에게 까다로운 입력입니다.
바른은 트랜스포머 기반의 분절·태깅 모델을 구어형·증강 데이터로 학습하고, 미등록단어를 문맥으로 추측하기 때문에
이런 표현에 강합니다. 이 문서는 바른이 구어·신조어에 어떻게 적응하는지를 설명합니다.
구어·신조어 처리 비교
| 항목 | 바른 | 사전 의존형 분석기 |
|---|---|---|
| 구어·축약형 | 구어형 학습으로 추측·복원 | 사전에 없으면 깨지기 쉬움 |
| 미등록단어(OOV) | 문맥으로 추측 + 출처 표시 | 추정 약함 |
| 신조어 반영 | 사용자 사전 무중단 추가 | 사전 재빌드 필요 |
| 형태 복원 | 활용·축약·생략 형태를 원형으로 복원 | 제한적 |
| 출처 구분 | out_of_vocab로 사전/추측 구분 |
보통 미제공 |
왜 구어에 강한가
바른은 품사를 붙이기 전에 "어디서 끊을지"를 전담하는 분절 단계를 둡니다. 구어체·축약형도 분절 단계에서
형태소 경계를 잡고, 활용·축약·생략된 형태를 원형으로 되돌립니다. 사전에 없는 표현이라도 AI모델이 문맥으로
그럴듯한 분석을 만들어냅니다. 어미가 나와야할 위치에 구어에서 변형이 이뤄지는 경우에 바른은 학습하지 않은
어미가 출현했음을 인지하도록 학습되었습니다. 이 때문에 다양한 어미 변화에 매우 유연합니다.
구어 적응력의 근거 — 대규모 음성·대화 데이터 보강
바른이 구어에 강한 것은 우연이 아니라, 실제 사람의 말에 가까운 데이터를 대규모로 학습했기 때문입니다.
표준 말뭉치에 더해 다음과 같은 음성·대화 기반 데이터셋으로 약 1억 어절 / 1,000만 문장을 보강했습니다.
| 데이터셋 | 성격 |
|---|---|
| 국립국어원 일상대화 2020 | 일상 대화체 |
| NIA 감정대화 | 감정 표현이 섞인 대화 |
| NIA 자유발화(일반, 10~50대 / 노인, 60대) | 연령대별 자유발화 구어 |
| NIA 한국인대화음성데이터 | 실제 대화 음성 전사 |
| NIA 회의음성데이터 | 회의 발화 |
| NIA 방언음성데이터 | 지역 방언 |
이렇게 자유발화·방언·회의 같은 실제 발화 데이터를 대규모로 학습했기 때문에, 사전에 정제된 문어체만으로는 다루기 어려운 축약·방언·구어 어미 변화를 폭넓게 흡수합니다. 학습에 쓰인 데이터의 전체 구성은 학습 데이터에서 다룹니다. 또한 학습 과정에서 저빈도 토큰은 모두 UNKNOWN으로 처리하도록 설계되어, 처음 보는 신조어가 등장해도 "모르는 단어가 나왔다"는 사실 자체를 인지하고 문맥으로 분석을 시도합니다.
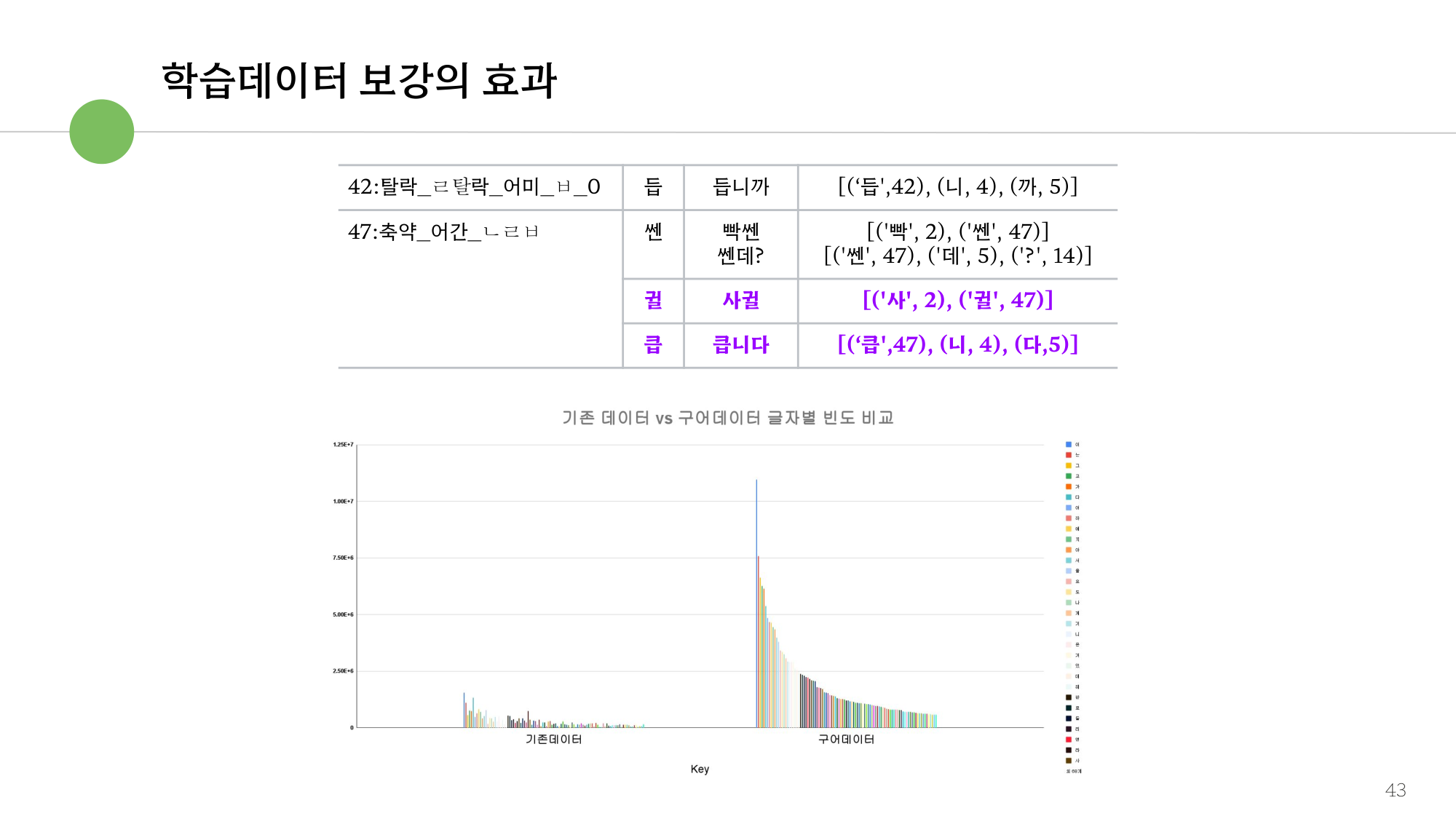 학습데이터 보강의 효과 — 음성·대화 데이터(약 1억 어절 / 1,000만 문장) 보강 전후 비교
학습데이터 보강의 효과 — 음성·대화 데이터(약 1억 어절 / 1,000만 문장) 보강 전후 비교
그래프 출처
위 그림은 발표 자료 「바른 맞춤법 검사의 내부 원리」의 "학습데이터 보강의 효과" 슬라이드에서 가져온 것입니다.
미등록단어를 추측하고, 출처를 밝힌다
바른은 사전에 없는 단어를 만나면 무조건 실패하지 않고, 모델이 추측한 결과에 출처 표시를 붙입니다.
결과를 받는 쪽에서 "추측으로 미등록단어로 팓단하는지", "사전에 출처가 있는 것을 기반으로 하는지"를 구분할
수 있습니다. 많은 미등록단어들이 내장된 사전을 참고하는 동안 사전을 출처로 변경되기도 합니다.
미등록단어를 추측하고 출처를 붙이는 방식은 미등록단어 처리에서 더 자세히 다룹니다.
사전에서 찾은 단어는 확률값이 없어요!
바른에서 사전에서 찾은 값으로 변환활 때에는 AI 모델이 원래 반환하는 확률값 정보를 버립니다.
probability 값이 0으로 바뀌게 됩니다.
각 형태소에는 학습 임베딩에서 왔는지, 모델이 자동 추측했는지, 또는 어느 사전(사용자·기본·우리말샘·위키·온용어)에서
왔는지를 나타내는 out_of_vocab 값이 함께 담깁니다. 덕분에 신조어가 잠정
추측인지 사전에 정식 등재된 것인지 응답 결과를 처리하는 쪽에서 판단할 수 있습니다.
값의 전체 목록과 각 값이 형태소 분석기·맞춤법 검사기에서 어떻게 표시되는지(우리말샘·위키·온용어 출처는 맞춤법 검사기 전용)는 형태소 분석 API — 학습하지 않는 단어 설명을 참고하세요.
형태 복원으로 구어를 되살린다
구어는 음운 축약·생략이 잦습니다. 바른은 후처리 과정에서 복원된 형태소가 원 음절의 정확한 위치를
갖도록 오프셋을 다시 계산합니다. 예를 들어 킨데요는 키+이+ㄴ데+요로 복원되며,
키·이·ㄴ데이 모두 같은 시작 위치를 가리키도록 처리합니다.
graph LR
A[구어 입력: 킨데요] --> B[분절·복원];
B --> C[키 + 이 + ㄴ데 + 요];
C --> D[원 음절 위치로 offset 복원];자체 말뭉치의 주요 내용
표준 말뭉치만으로는 충분히 다루기 어려운 구어·축약·불규칙 활용·미등록 명사 등을 직접 보강한 자체 말뭉치(약 33만 어절)를 함께 학습합니다. 주요 내용은 다음과 같습니다.
- 불규칙 활용·음운 변동 보강: ㅂ·ㅅ·ㅎ·ㄹ·러·르 불규칙, ㄹ 탈락, '으' 첨가, 반모음 결합 등 활용 과정에서 형태가 바뀌는 사례
- 구어체·축약 어미 보강: '-잖아/-잖네', '-죠', '-네', '-셔/-셨', '-래/-랬', '-쇼/-슈'처럼 실제 말에서 자주 나타나는 어미 변형
- 자주 틀리는 축약 표기: '되/돼', '뵈/봬', '외/왜'처럼 혼동하기 쉬운 축약형을 올바르게 분석하도록 학습
- 방언 어미 보강: 지역 방언에서 나타나는 종결·연결 어미('-었-' 계열 변형 등)
- 명사 + 서술격조사 '이' 복원: 받침 유형별로 일반명사(NNG)·고유명사(NNP) 뒤에 숨은 '이'(서술격조사 VCP)를 되살리는 사례 (예:
평갑니다→ 평가/NNG+이/VCP+ㅂ니다/EF) - 품사 태깅 보강: 연결·종결 어미(EC·EF), 조사(주격 JKS·목적격 JKO·관형격 JKG·부사격 JKB·보조사 JX 등), 파생접사(XSN·XSV·XSA)처럼 헷갈리기 쉬운 태깅 사례
- 띄어쓰기 증강: 붙여 쓰거나 잘못 띄운 어절도 형태소 경계를 바르게 잡도록 보강
- 수사·특수기호 처리: 한글 수사(NR), 특수기호·영어 구두점 같은 비문자 토큰
- 중의성(모호성) 보강: 같은 표면형이 문맥에 따라 다르게 분석되는 경우(예: '가'가 동사 VV인지 보조용언 VX인지)를 구분하도록 학습
왜 직접 보강하나요
표준 말뭉치는 정제된 문어가 중심이라, 구어 어미 변형이나 불규칙 활용·미등록 명사 같은 사례가 상대적으로 적습니다. 이런 저빈도·고난도 사례를 자체 말뭉치로 채워, 분절과 품사 태깅이 실제 입력에서 더 고르게 동작하도록 합니다.
우리말 쓰임새에서 보면 부족한 데이터도 많아요.
실제 한국어 쓰임에는 표준 말뭉치가 충분히 담지 못한 표기·활용이 많습니다. 바른은 개발하면서
분석이 틀리는 사례를 찾을 때마다 자체 말뭉치로 채워 왔습니다. 아래는 그동안 표준 말뭉치에
부족해 따로 보강해 온 대표적인 사례들입니다.
| 보강한 사례 | 구체 예시 |
|---|---|
| 저빈도 음절·레이블 | 출현 빈도가 낮아(예: 빈도 5 이하) 정확도가 떨어지던 음절 단위 표현을 집중 보강 |
| 불규칙 활용 | ㅂ·ㅅ·ㅎ 불규칙, ㄹ 불규칙('으' 첨가), 르 불규칙(어간 'ㄹ' 첨가) |
| 음운 축약 오류 | '되/돼', '뵈/봬', '외/왜', '어었' 등 자주 틀리는 축약형, 인용 축약('돼라는', '달라란') |
| 명사 뒤 서술격조사 '이' 복원 | '걘·껍·난·낸'처럼 "명사+이+어미"가 줄어든 형태, 종성 없는 명사+이+시+오('쇼/슈'), '조사+이+어미'('에서+이+ㄴ지', '부터+이+ㄹ까') |
| 띄어쓰기 | 관형격 조사 '의' 띄어쓰기, 만 단위 수 띄어쓰기, 띄어쓰기 뒤에 나오는 '란' |
| 방언 어미 | 지역 방언에서 나타나는 '-었-' 계열 종결 어미 |
| 비표준어·구어 동사 활용 | '이카다/저카다'('ㅣ' 모음 순행동화), '않아하/않아해', '긇지·요렇케·시끄러' |
| 명사형 전성어미 | 본용언과 보조용언을 붙여 쓰는 개조식 명사형 |
| 저빈도 어휘·표현 | '누차', '-을 뻔하-', '난이도' 등 |
| 특수기호·외국어 표기 | 흔치 않은 기호가 섞인 문장, 영어 구두점, 로마자(SL) 표기 |
신조어는 사용자 사전으로 즉시 보강
학습에 포함되지 않은 신조어·전문용어는 사용자 사전에 등록해 보강할 수 있습니다.
사용자 사전은 DB를 사용하지 않고, 서버의 파일시스템에 기록됩니다. 새로운 사전이 추가되거나
등록된 사전이 변경되는 것을 바로 감지할 수 있습니다. 바른은 이 이벤트를 모니터링하여
무중단으로 반영하므로, 새 용어가 생길 때마다 서버를 멈추지 않고 즉시 분석에 적용할 수 있습니다.
고유명사·복합명사·동사·형용사·관형사·부사·감탄사를
사전 종류별로 등록할 수 있습니다.
비교 시 유의
다른 분석기도 사전 추가나 일부 미등록단어 추정을 지원할 수 있습니다. 다만 구어형 학습 데이터, 문맥 기반 추측, 출처 표시, 무중단 사전 반영의 조합은 도구마다 다릅니다. 구체 동작·수치는 각 도구의 버전·문서로 확인하세요.
관련 문서
- 미등록단어 처리 — 사전에 없는 단어를 추측하는 원리
- 학습 데이터 — 구어·증강 데이터 구성
- 사용자 사전으로 미등록단어 줄이기 — 신조어를 사전으로 보강
자주 묻는 질문
Q. "감사합니당" 같은 구어체도 분석되나요?
바른은 구어형·증강 데이터로 학습되어 이런 축약·구어 표현을 분절하고 원형으로 복원하려 시도합니다.
사전에 없더라도 문맥으로 추측하며, 결과에 미등록 여부를 표시합니다.
Q. 새로 생긴 신조어는 어떻게 반영하나요?
사용자 사전에 등록하면 됩니다. 바른은 사전 변경을 무중단으로 감지해 다음 요청부터 바로 반영합니다.
재시작이 필요 없습니다.
Q. 추측한 단어인지 사전에 있는 단어인지 알 수 있나요?
네. 각 형태소의 out_of_vocab 값으로 워드 임베딩·자동 추측·사용자 사전·기본 사전·우리말샘 등
어디에서 온 결과인지 구분할 수 있습니다.
Q. 바른은 구어를 다루기 위해 어떤 데이터를 학습했나요?
표준 말뭉치에 더해 국립국어원 일상대화, NIA 감정대화·자유발화·한국인대화음성·회의음성·방언음성 등 음성·대화 기반 데이터로 약 1억 어절 / 1,000만 문장을 보강했습니다. 자유발화·방언·회의 같은 실제 발화를 대규모로 학습해, 문어체만으로는 다루기 어려운 축약·방언·구어 어미 변화에 강합니다.
도움이 되었나요?